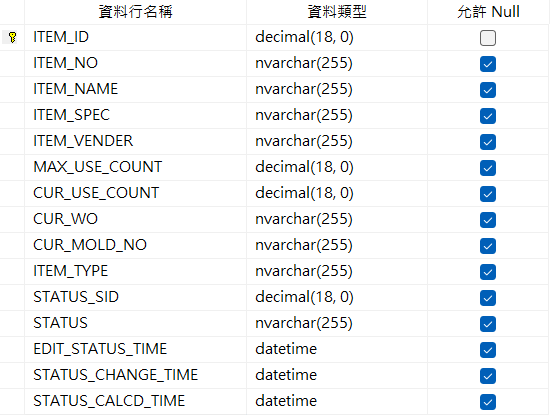
你能一眼看懂下列欄位嗎?
ITEM_ID、ITEM_NO、ITEM_VENDER、MAX_USE_COUNT、CUR_USE_COUNT、CUR_WO、CUR_MOLD_NO…
我第一眼看到時:尛,怎麼全部大寫,為什麼要縮寫。
| 欄位 | 問題 | 解法 |
|---|---|---|
ITEM_ID |
語意模糊,無法辨識是「料件」、「設備」還是「工單」 | 明確命名:EquipmentId、ToolingId |
ITEM_VENDER |
拼字錯誤(Vender 應為 Vendor),ORM 映射會尷尬 |
改欄位名稱或在 ORM 先 mapping 成別名 |
CUR_* |
CUR 縮寫不明(Current?Currency?Stephen Curry?) |
全名化:CurrentWorkOrderNo、CurrentMoldNo |
MAX_USE_COUNT / CUR_USE_COUNT |
定義模糊,不知是「可用上限」vs「目前使用次數」還是「歷史最大值」 | 明確定義 |
| 欄位/結構 | 問題 | 解法 |
|---|---|---|
PK decimal(18,0) |
PK,風險包含撞號與交易鎖等待 | 改用 INT/BIGINT IDENTITY 當叢集鍵,GUID 作唯一非叢集索引(Clustered 與 PK 可分離,詳見後文) |
萬能 nvarchar(255) |
問題不大,但是無法反映實際長度需求,浪費儲存空間和 I/O | 依需求調整:NVARCHAR(40)、NVARCHAR(100) 等 |
STATUS_SID + STATUS |
既然有 STATUS_SID ,應該有正規化,幹嘛存STATUS留下有機會不同步的風險 | 保留SID(FK),名稱 JOIN 字典表取得 |
| 問題 | 風險 | 解法 |
|---|---|---|
| 欄位過長 + 缺索引 | 查詢慢、全表掃描 | 根據查詢模式建立適當索引,並調整欄位長度 |
| 文本欄位隨意使用 | 容易發生 XSS、資料污染 | 前後端皆需輸入驗證、長度限制與內容過濾 |
| PK 設計不合理 | 並發寫入易失敗、索引碎片化 | 採用合理 PK 型別與生成策略,降低鎖爭與 Page Split |
NVARCHAR(255) / NVARCHAR(MAX) 會放大索引頁,降低 page 密度,I/O 開銷變大VARCHAR 與 NVARCHAR 混用)改進方向
NVARCHAR(40))<script>alert(1)</script> 直接進資料庫並渲染改進方向
maxlength、pattern、格式驗證使用 decimal(18,0) 作為叢集鍵(Clustered PK):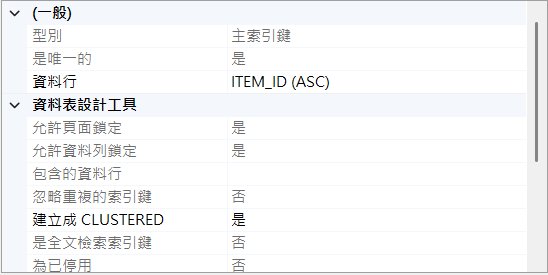
鍵值過大 → 索引層級加深
decimal(18,0) 單鍵約 9 bytes,int 是 4 bytes、bigint 是 8 bytes。
以 8KB 資料頁為例(可用約 8096 bytes),索引內部節點粗略估算:
int:鍵(4) + 指標(8) ≈ 12 bytes → 一頁可放 ~674 個鍵。
decimal(18,0):鍵(9) + 指標(8) ≈ 17 bytes → 一頁僅 ~476 個鍵。
結果:同樣 100 萬筆資料,decimal 的 B-Tree 層級較深、遍歷頁數更多,搜尋與範圍掃描 I/O 增加。
非遞增插入 → Page Split(頁分裂)與碎片化
具體例子:某頁(Page #123)已依鍵排序存放 100000000000000001 ~ 100000000000000100 共 100 筆。
新插入鍵 100000000000000050(中間位置),該頁已滿 → Page Split:
分配新頁(Page #456)
搬 Page #123 後半段(約 50 筆)到 #456
把新資料插回正確頁面
更新父節點指標(索引重連結)
代價:8KB 頁搬運 + 大量 Transaction Log;若插入長期非末尾(例如應用程式計算、批次回填),碎片化比例可飆 >30%,範圍查詢明顯變慢。
放大所有非叢集索引(NCI)成本
在 SQL Server,NCI 葉節點會附帶從叢集鍵作為 Row Locator。
叢集鍵若是 decimal(18,0)(9 bytes),所有 NCI 都會跟著變胖,百萬筆時索引體積、記憶體占用、I/O 全面上升。
結論/建議:
不要用 decimal(18,0) 做叢集鍵。
最佳解:int identity/bigint identity 做 Clustered PK(單調遞增、減少分裂)。
若不想改 decimal ,改建 Nonclustered Unique Index 維持唯一性,不要拿它當叢集鍵。
需要對外不可猜的 ID → 另加 PUBLIC_ID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID(),建立 Unique NCI 對外用,內部仍以遞增鍵為主。
改善建議
採用 INT SEQNO 遞增 Clustered Index + Guid ID 非叢集唯一索引,同時兼顧效能與安全性。
(參考:Darkthread〈GUID 當 PK 的取捨〉)
CREATE TABLE dbo.Tooling (
SeqNo INT IDENTITY(1,1) NOT NULL,
Id UNIQUEIDENTIFIER NOT NULL
CONSTRAINT DF_Tooling_Id DEFAULT NEWSEQUENTIALID(),
ToolingNo NVARCHAR(40) NOT NULL,
Vendor NVARCHAR(100) NULL,
-- ...
CONSTRAINT PK_Tooling_Id PRIMARY KEY NONCLUSTERED (Id) -- PK = Id(非叢集)
);
GO
CREATE CLUSTERED INDEX CX_Tooling_SeqNo ON dbo.Tooling(SeqNo); -- 叢集在 SeqNo(遞增)
SeqNo(INT/BIGINT Identity、Clustered Index)
遞增數值 → 插入落在最後一頁,降低 Page Split
窄鍵(INT/BIGINT)讓 B-Tree 更淺,提升查詢/排序效能,B-Tree 與鍵大小掛鉤
分頁、排序、批次處理都吃得到好處。
Id(GUID、Nonclustered Index / PK Nonclustered)
為對外唯一識別碼,適合 API 曝光,避免順序 ID 被推測
非叢集設計避免 GUID 當 clustered 的碎片化災難
B-Tree 與鍵大小掛鉤 範例對比
| 型別 | 鍵大小 | 指標大小 | 一頁可放鍵數 | 影響 |
|---|---|---|---|---|
| INT | 4 B | 8 B | ~674 | 樹最淺 |
| BIGINT | 8 B | 8 B | ~506 | 稍深 |
| DECIMAL(18,0) | 9 B | 8 B | ~476 | 更深 |
| GUID | 16 B | 8 B | ~347 | 最深 |
查詢路徑示意(為什麼查 GUID 看起來會用 SeqNo?)
WHERE Id = @guid │ ├─ Index Seek on (Id) ──> 先在 Id 的 NCI 找到這列的叢集鍵「SeqNo」 │ └─ Key Lookup (Clustered on SeqNo) ──> 用 SeqNo 回到 Clustered 取完整那一列
API 對外回傳 Guid,難以暴力猜測。
多資料中心或離線批次產號時,Guid 保證全域唯一性。
ORM 可直接映射 Id(Guid)作為識別碼,SeqNo 作為內部排序與關聯用。
避免像 ITEM_ID 這種模糊命名,改用明確名詞(ToolingId、EquipmentId)。
合併多系統資料時,Guid 避免撞號。
SeqNo 保留本地資料寫入的高效能。
這張表的特徵是:
命名靠猜、型別不佳、效能看緣分,最嚴重的是 PK 設計不合理,所以我多著墨了一點
所以以後我自己會盡量保持:


 iThome鐵人賽
iThome鐵人賽